
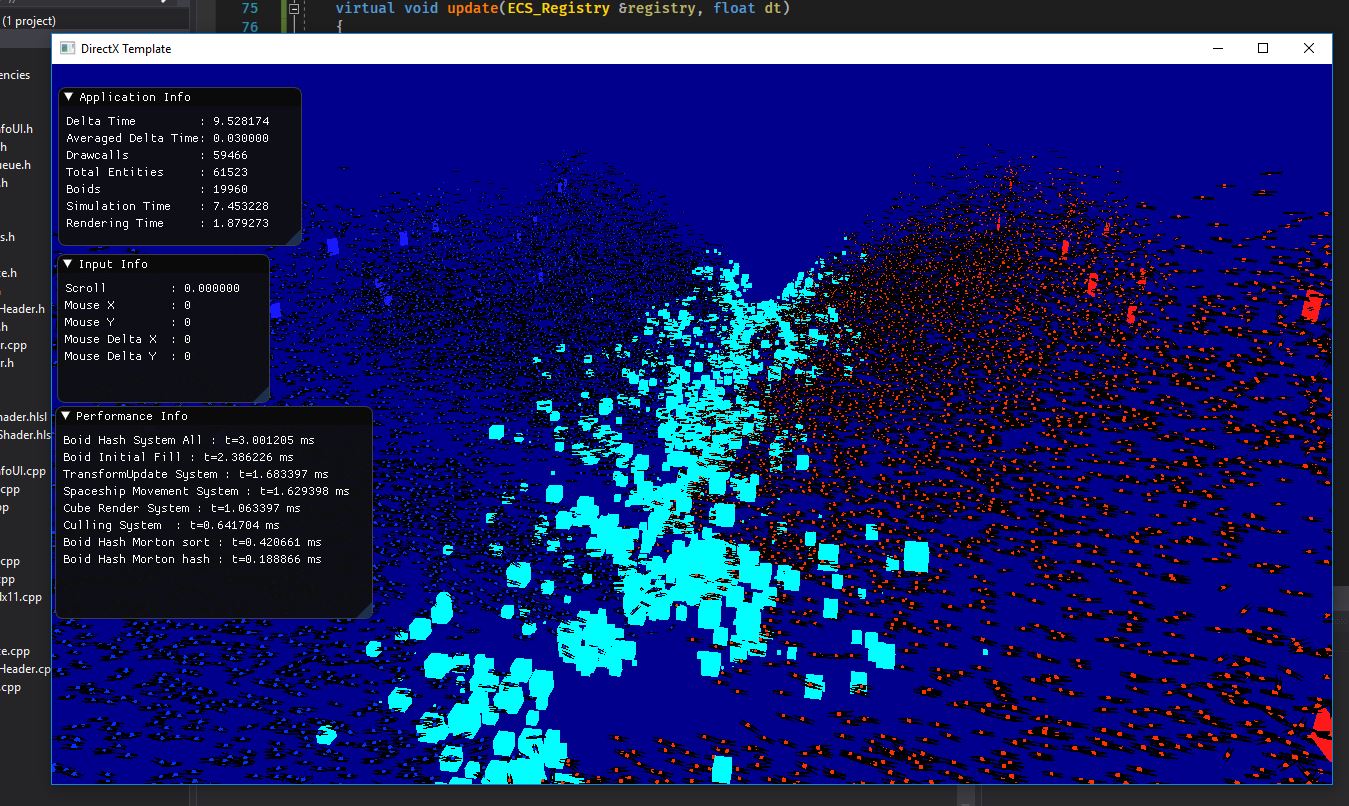
After getting bottlenecked by UE4 on the last ECS battle simulation Link , I decided to create one on direct C++,using an engine written by me.
The new simulation simulates 130.000 entities at 60 fps on my Ryzen machine. It is designed in a way that it almost scales linearly with cores.
The simulation is very similar to the UE4 version, it runs around 40.000 “spaceships”, all of them with a separation kernel to move in the opposite direction of their peers. This part takes most of the CPU time. The spaceships fly for a while and then explode.
The render engine uses DirectX instanced rendering, to render huge amounts of colored cubes, all of them with a different transform, wich is recalculated every frame.
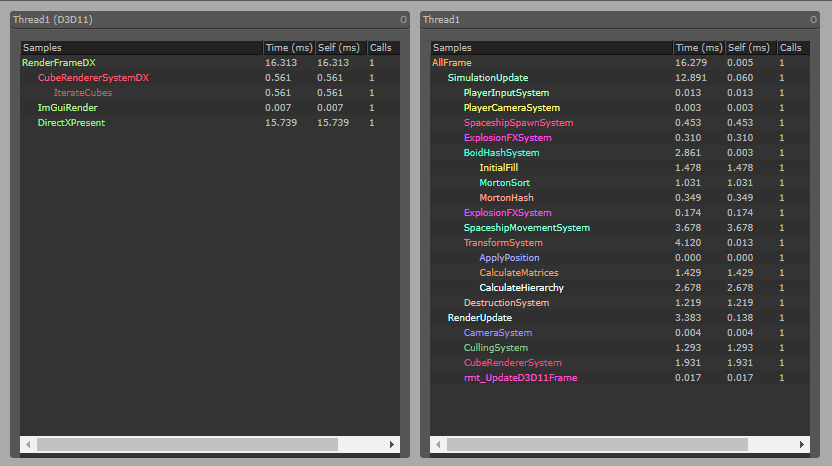
Performance of the simulation (recorded with Remotery )
Parallelism
The engine uses EnTT in a similar way to the UE4 simulation, but the main difference is that most of the systems on it are multithreaded. Unlike the UE4 version, I made sure to make almost everything run as a “parallel for”. The speedup in those systems hovers around 6 to 8 times faster with multithread (Ryzen with 8 physical cores and hyperthreading)
To keep the multithread part as simple as possible, I use the C++17 “parallel STL” extensively. With some modification to the Entt views, I was able to use “std::for_each()” on them, with the parallel execution policy to run the simulation lambda on every thread.
I want to eventually modify it to use a Job system, and to be all in a fully parallel graph to reach 100% core usage over all threads. At the moment it has some serial parts wich slow it down a bit and could be pipelined.
The whole simulation uses no locks other than a couple atomic variables. The way it works is that the main thread loops over every system of the engine in order, and some of the systems use a parallel for. The parallel for is an atomic “kernel” that can only access its own variables, wich makes data races imposible. As the main thread is the one executing every system, there are some singlethreaded parts, and thats where the engine goes serial for a while until it enters another parallel for or parallel algorithm. Im using for_each(par) and sort(par) in the simulation.
Example:
//copy every entity of the view into the Mortons array (calculates morton too)
std::for_each(std::execution::par,Boidview.begin(), Boidview.end(), [&](const auto entity) {
//this is done in as many threads as the STL decides, usually all
auto[t, boid] = Boidview.get<TransformComponent, BoidComponent>(entity);
AddToGridmap(t.position, boid);
});
Parallel Sections

Boid Avoidance
The most complicated part of the simulation is the boid avoidance, and it takes 50% of the simulation time. It consists on 2 parts. The first part builds a acceleration structure, and then a different system uses this acceleration structure to find the nearby units and perform avoidance.
I tried multiple ways of doing it, and eventually settled on a very simple basic array, sorted by morton code, and then I do a binary search on that to find what I need.
At first, I tried the same way the unreal engine ECS uses, wich is creating a hash map of “tiles”, and then adding the entities into those tiles. The data structure is basically
HashMap< GridCoordinates, Vector< Boid > >;
This worked great in the unreal engine version, because the unreal engine only writes to the ECS the spaceships (around 1000 on the higher end), and does it sequentially. Then the bullets read from it very fast to perform their heat-seeking behavior. As in the new simulation I dont have heat seeking missiles, but only spaceships (and 40.000 of them), this did not scale. Inserting 40.000 entities into a hash map takes time, and its not very friendly to parallelism. For that reason I looked at alternatives, like using better hashmap implementations than std::unordered_map, but while those were twice faster than unordered_map, it still was not enough.
Then I turned into the idea of sorting the grid somehow, and using a binary search on it. My research got me to morton codes (Z-order curve) wich is a way to map a 2d coordinate into a 1d line, and that way is done in a way that it preserves locality very well. I used an implementation of a 3d version of the algorithm for this, wich allowed me to almost fully parallelize the “insertion”, and then the reads can be parallel too.
The current algorithm first reserves an array of the same size as all the boids in the world. Then it does a parallel_for over every boid in the world to calculate the morton code of its “grid” and insert the BoidData needed into the array (atomically, unsorted). Once the array is filled with every entity in the world, I use std::sort(parallel) to do a parallel sort over it. Being parallel, sorting such a huge amount of units doesnt really cost that much, and I sort them by their morton code.
//parallel sort all entities by morton code
std::sort(std::execution::par, boidref.map->Mortons.begin(), boidref.map->Mortons.end(), [](const GridItem2&a, const GridItem2&b) {
if (a.morton == b.morton)
{
//use the lengt of the vector to sort, as at this point it doesnt matter much
return XMVectorGetX(XMVector3LengthSq(a.pos)) < XMVectorGetX(XMVector3LengthSq(b.pos));
}
else
{
//sort by morton
return a.morton < b.morton;
}
});
Now I could already do a binary search over this, but this array is still “too big”, so I create a second array, wich is exclusively to have the TileData
struct TileData{
uint64_t morton;
uint32_t start_idx;
uint32_t end_idx;
}
This allows me to accelerate the binary search, as I can do the search on this second array, and once ive found the TileData of the exact Tile I want to unpack, I have the range of the main array. Generation of the TileData array is singlethreaded, because it relies on a linear “packing” of the boid data.
Typical sizes are around 1000 TileData array vs 40.000 BoidData array.
To find the nearby boids to a location, first I calculate the tiles that would fall inside the search radius, and then I try to find each Tile morton code in the TileData array (through binary search). Once that is found, I iterate over the range that the TileData gives me.
Transform Matrix System
As this is on a custom engine, and not under unreal engine, I had to implement my own node tree, and generate my transform matrices. To do that, I decided to look at the way the paper “Pitfalls of Object Oriented Programming” implemented a scene graph in a data oriented fashion.
Instead of having an actual “scenegraph”, I have a tree of transforms. But the interesting part is that the transforms are stored in contiguous arrays by tree depth. I have one array for each hierarchy level, and each of those arrays hold a transform matrix + a “parent” index (16 bit as its enough ).
To calculate the transforms of up to 130.000 objects every frame, I first start by building the model matrix out of the position, rotation, and scale components. To do that, I perform a parallel for that iterates over the data of every entity, and stores the calculated matrix into the correct scene tree position. This ones are all “relative” to the parent.
Once all the transforms are calculated, I need to calculate the actual parent/child relationship, to get the final “world” matrix for rendering. To do that, I do a parallel for over every level of the scene tree IN ORDER, starting by the nodes at level 1 (as the level 0 nodes do not have a parent so they dont need further calculation), and ending when everything is calculated. Every level is fully calculated before starting the next, and the transform matrices are calculated by their “in-memory” order, as they are stored in contiguous arrays. This makes it super cache friendly, and 100% multithreaded with linear scaling.
Once every transform of every object is calculated, its time to render them.
Rendering System
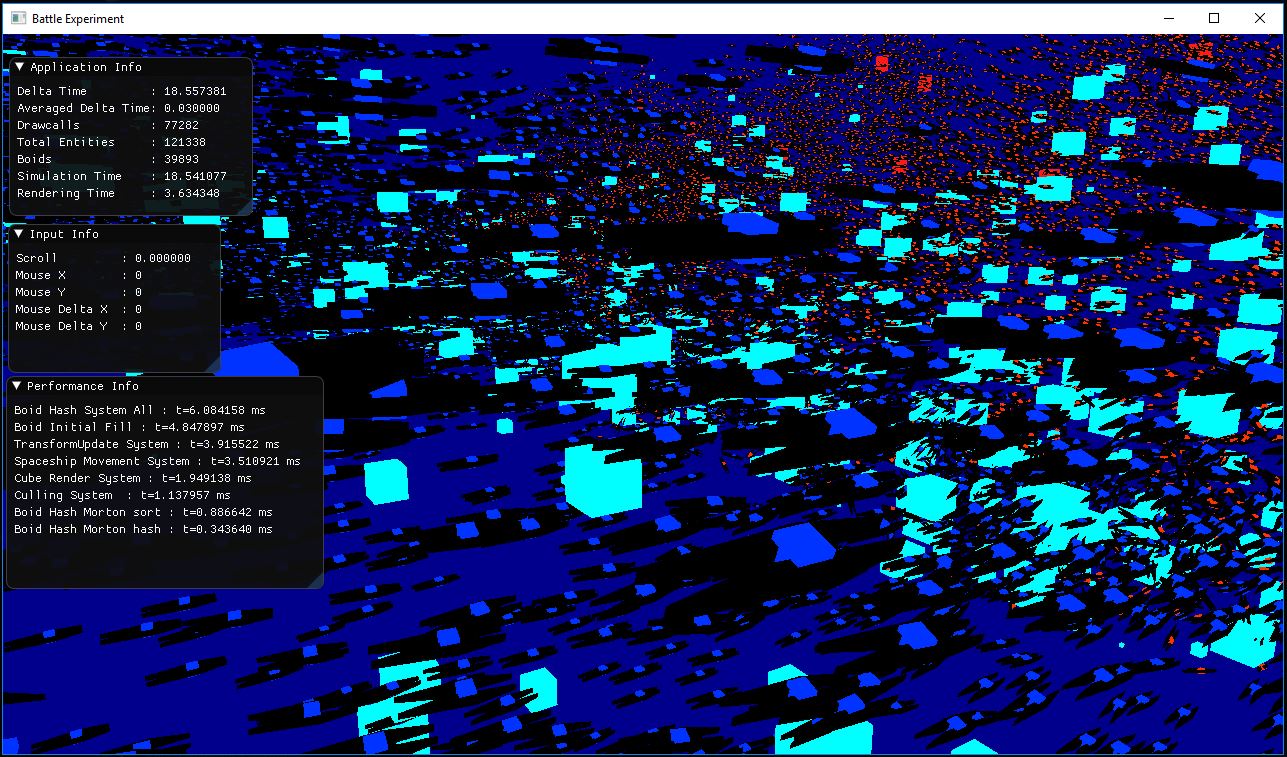
Everything up to this point has been API agnostic, but I chose DirectX for the rendering API. The reason is that I dont have as much experience with directx as with opengl, so I wanted to learn more.
The API part of the rendering is done single-threaded because directx doesnt really like multithreaded rendering unless its very carefully done, wich I didnt want to do.
At this moment, the engine can only render cubes at arbitrary transform matrices and colors. It does not do anything else (i want to upgrade it to arbitrary models soon).
Before submitting the calls to directx, I perform culling. This culling is a VERY simple frustrum culling, done multithreaded. I use the transform matrices calculated in the last step to transform a bounding sphere, and then I check that sphere against the frustrum. Done with a trivially simple parallel for.
To do the “Actual” rendering, I first setup the correct uniforms, buffers, and programms for my cube and my default colored cube shader. Once everything is setup, I render the cubes in a instanced fashion. I iterate over every one of the “visible” cubes, and add them into a uniform buffer array. Once a batch size has been reached (512 in the demo), it is uploaded to the GPU and rendered with a Draw Instanced call.